Smart Options via the SLP_SmartOptions class (include/module/smartoptions/SLP_SmartOptions.php) handles nearly all of the settings (options in WordPress parlance) for the Store Locator Plus® plugin.
Methods
get_ValueOf( <property:string> )
Get the value of a Smart Option.
Check if a given property exists and return the value.
@param string $property The property to check.
@return bool Returns true if the property exists and is not null, and its 'is_true' property is true. Otherwise, returns false.
is_true( <property:string)
Check if a given property is true. @param string $property The property to check. @return bool Returns true if the property exists and is not null, and its ‘is_true’ property is true. Otherwise, returns false.
if ( SLP_SmartOptions::get_instance()->is_true( 'use_territory_bounds' ) ) {
$this->add_territory_bounds();
}
We are going to move away from manually-executed grunt tasks via the wp-dev-kit repository and move toward an AWS implemented solution. We are going to leverage AWS developer tools to get the job done.
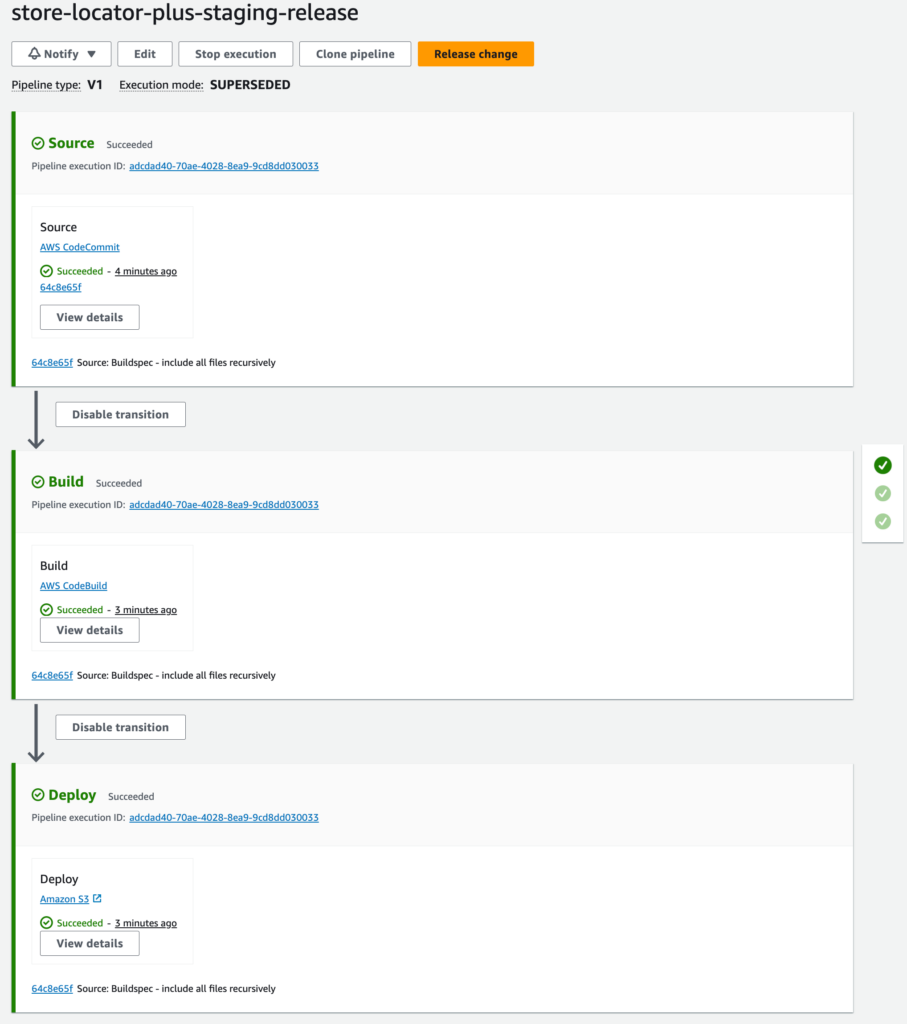
The general process is that you work on code and merge it into the develop branch of the store-locator-plus repository on CodeCommit (the main upstream source). When that code is deemed “ready for testing” the repo manager will merge the develop branch into the staging branch for the repository. CodePipeline should see the change to the staging branch in the repo and fire off the build and deployment processes.
CodeCommit
The repo, and now official “source of truth” for the SLP code and build kit repositories.
The build manager that will compile , minify, clean, and otherwise manipulate the stuff in the main SLP repo and prepare it for release. In this case a staging release of the WordPress plugin .zip file.
CodePipeline
Watches the main SLP repo for changes on the staging branch and fires off the CodeBuild execution when that happens.
Note that the CodePipeline takes over the artifact generation output and will dump the final output artifact store-locator-plus.zip into a different CodePipeline specific bucket. This is NOT the same bucket that is specified in the CodeBuild configuration.
Deploy
This is a setting in CodePipeline, NOT a CodeDeploy project, that copies the output artifact (store-locator-plus.zip) from the private CodePipeline artifacts bucket over into the storelocatorplus/builds/staging bucket.
S3 Buckets
This process uses S3 buckets to store build and pipeline artifacts.
The deployment process uses a public web endpoint (HTTP, non-secure) to store the final output artifact alongside some other SLP “goodies”.
The phpDocumentor tool is used to generate the docs via a Docker image. You will need Docker installed to generate the docs.
In the main plugins directory (~/phpStorm Projects/WordPress/wp-content/plugins) drop in the following phpdoc.dist.xml file. This version will generate documentation for the SLP and Power add on in a single HTML subsite.
The locator layout should be able to set any setting in SLP.
The Default Locator Style was updated to change “label_phone” from “Phone” to “Phone ” on the main Store Locator Plus® site (this is managed in the Premier Services plugin).
Problem
Setting the label_phone with a space at the end is not making it to the settings on a user site. It appears as though trim() is being called when the data is recieved.
Research
Cannot reproduce after fixing some JavaScript errors on the admin processor.
The process that happens when a plugin is updated, especially the conversion of pre-existing options to SLPlus options / options_nojs serialized JSON objects.
In older releases , including some vestiges that still existing in 2209.X versions, options were stored in a WordPress option_name that match the plugin name. Such as option_name ‘slp-power’ for the power add on. Each add on had its own set of options.
When Smart Options were introduced into the SLP architecture there were two options that stored “all settings”. csl-slplus-options (aka “options”) stores settings that were not being localized and sent to JavaScript. csl-slplus-options_nojs (aka “options_nojs”) are the settings that are not localized. (In theory… both of these will be replaced with a single monolithic store in csl-slplus-options eventually and specific settings retrieved from JavaScript via a REST call).
The idea was to eventually (soon?) convert all separate plugin-specific option settings like option_name = ‘slp-power’ into a standard csl-slplus-options string. Below is the flowchart that describes how that conversion happens.
Store Locator Plus® was updated with a “pub/sub” model a few years ago. This feature is a managed interface for jQuery Callbacks that allows disparate Javascript functions to interact with each other. It works much like hooks and filters in WordPress, but solely within the JavaScript runtime space.
The basic premise is any JavaScript function can call a “publish” method that fires off a stack of callbacks.
slp_Filter('slp_map_ready').publish(cslmap);
What is run by those callbacks is set by having a JavaScript module call a “subscribe” method.
Location bulk actions allow for users to work on multiple locations at once. Export a list of locations, delete select locations from the location table, geocode locations ,and more.
2209.12
Export locations is our first attempt at making bulk actions work more like a single page application.
Instead of doing a form post and submitting the location list, then reading in some PHP-driven variables to set the JavaScript behavior — in 2209.12 the export process bypasses the form submit.
Bypass is handled by using a pub/sub module with a dynamic filter name “exportBulkAction”. This tells the main SLP JavaScript process to execute the callback stack instead of pushing a form submit. This allows the AJAX call to happen immediately without a full page re-render.
2208.15
The apply button processing is handled in the main plugin’s admin.js file.
It uses jQuery to process form variables and prepare the #locationForm to be submitted.
When submitted it sends the request back to WordPress for standard “full page load” processing.
The process starts with a standard form submit from the Bulk Actions “Apply” button.
WordPress sets up a JavaScript variable location_import that has info about the action “export”.
This triggers a jQuery(document).ready() call that fires another request via AJAX back to WordPress with some new parameters in place.
That AJAX call eventually sends back a CSV file that is stored in a DOM div that was prepared with the jQuery() document loader when the refreshed page (post original submit) was rendered.
All development is done on personal forked copies (origin) of the primary Store Locator Plus® repositories (upstream). Upstream is considered the “single source of truth” for the current code state.
To begin work, fork the main Store Locator Plus® repository (upstream) to a personal repo (origin).
When code is ready to be integrated with current ongoing development effort, issue a pull request for your origin:update/<something> (see branch conventions below) branch into the upstream:develop branch. When the pull request is approved and merged, the upstream:develop branch be ready for the rest of the team.
Monitor upstream:develop regularly and be sure to fetch-and-merge (aka “pull”) the upstream:develop branch into origin:develop. Any in-progress origin:update/<something> branches that have not had a pull request issues against upstream should be rebased onto the new origin:develop branch. Make sure all conflicts are resolved.